
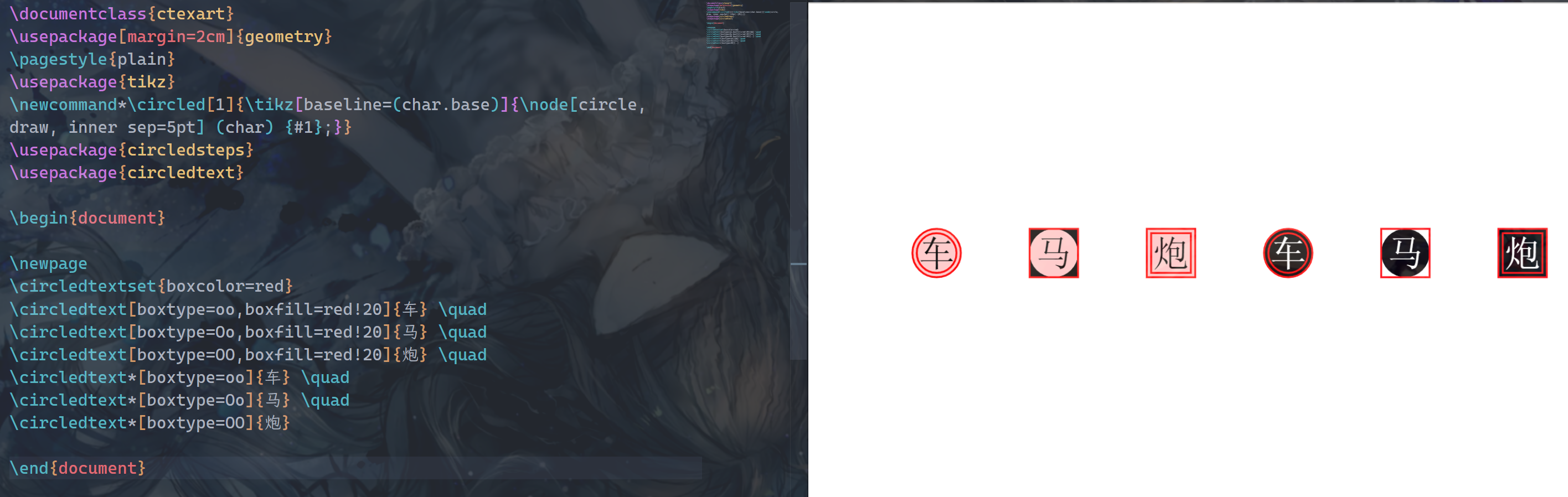
也可以用你自己用的syntax:cell{}{}={}{}
\documentclass{article}
\usepackage{xcolor}
\usepackage[scale=0.8,papersize={10.5cm,14.85cm}]{geometry}
\usepackage{tabularray}
\pagestyle{empty}
\begin{document}
\begin{center}
\begin{tblr}{
hlines,vlines,
colspec={X[c,m]X[c,m]X[c,m]X[c,m]X[c,m]X[c,m]},
% cell{3,4}{4,5}={bg=green!30},
% cell{3,4}{6}={bg=red!30},
% cell{5,6,7}{6}={bg=blue!30},
cell{3}{4} = {r=2,c=2}{c,m,bg=green!30},
cell{3}{6} = {r=2,c=1}{c,m,bg=red!30},
cell{5}{6} = {r=3,c=1}{c,m,bg=blue!30},
% stretch = 0,%
}
1-1&1-2&1-3&1-4&1-5&1-6\\
2-1&2-2&2-3&2-4&2-5&2-6\\
3-1&3-2&3-3&3-4& &3-6\\
4-1&4-2&4-3& & & \\
5-1&5-2&5-3&5-4&5-5&5-6\\
6-1&6-2&6-3&6-4&6-5& \\
7-1&7-2&7-3&7-4&7-5& \\
\end{tblr}
\end{center}
\end{document}多读读文档,其实是有现成的例子抄的~

















问 在`tabularray`的`X[c,m]`格式下,如何合并单元格?